
7 min read
What the State of AI 2026 Survey Says About Developer Work
A developer-focused summary of the State of AI 2026 survey, covering adoption, coding agents, paid usage, costs, risks, and what engineering teams should take from it.
A developer-focused summary of the State of AI 2026 survey, covering adoption, coding agents, paid usage, costs, risks, and what engineering teams should take from it.
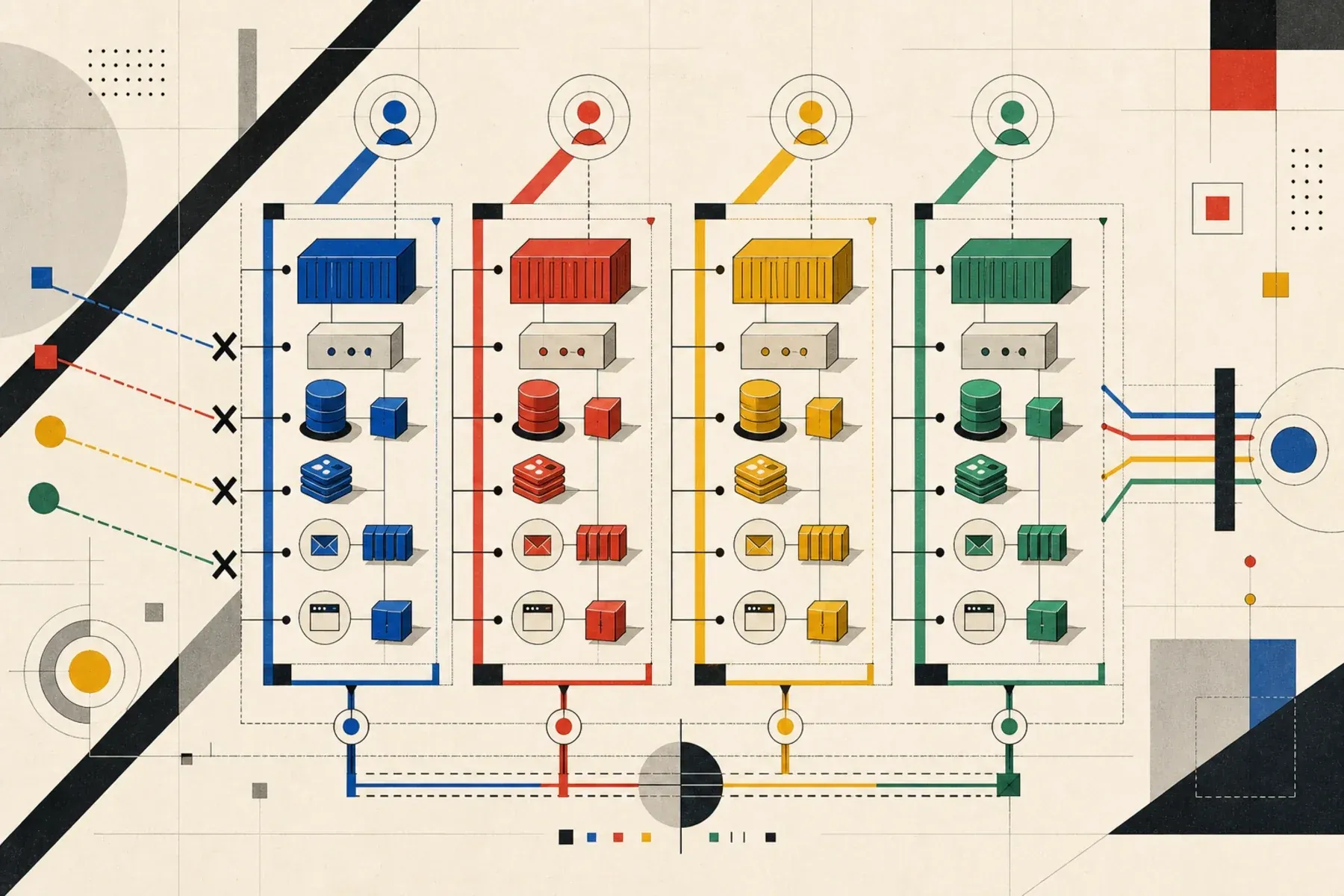
How to structure Docker Compose so several AI coding agents can run the same multi-container Laravel app at the same time without clashing over ports, volumes, databases, or seed data.

Why AI coding tools only create lasting velocity when leaders fix trust, feedback loops, governance, and engineering fundamentals.
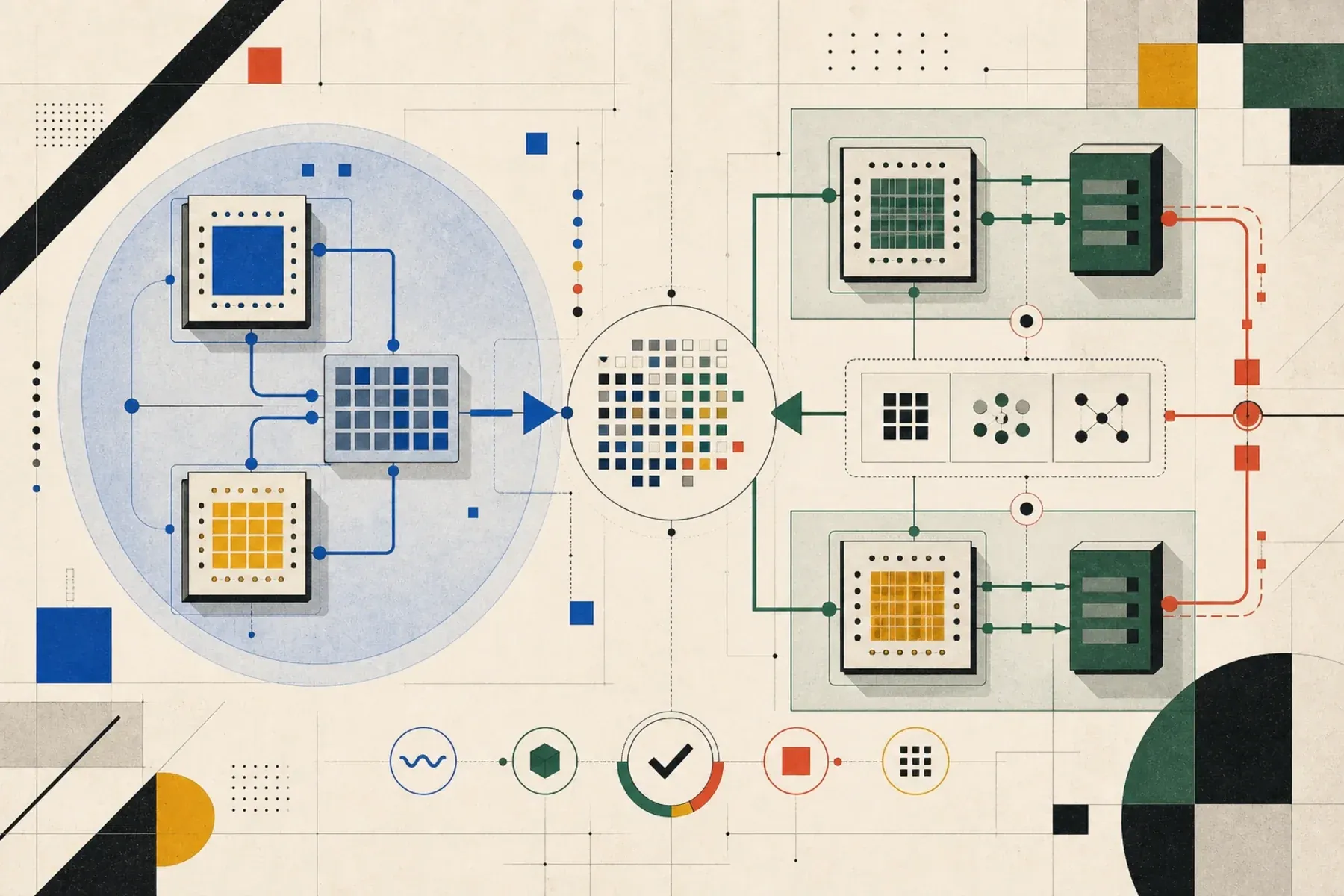
A practical comparison of Apple MLX and NVIDIA CUDA, where they overlap, where they differ, and how those differences should shape your choice.
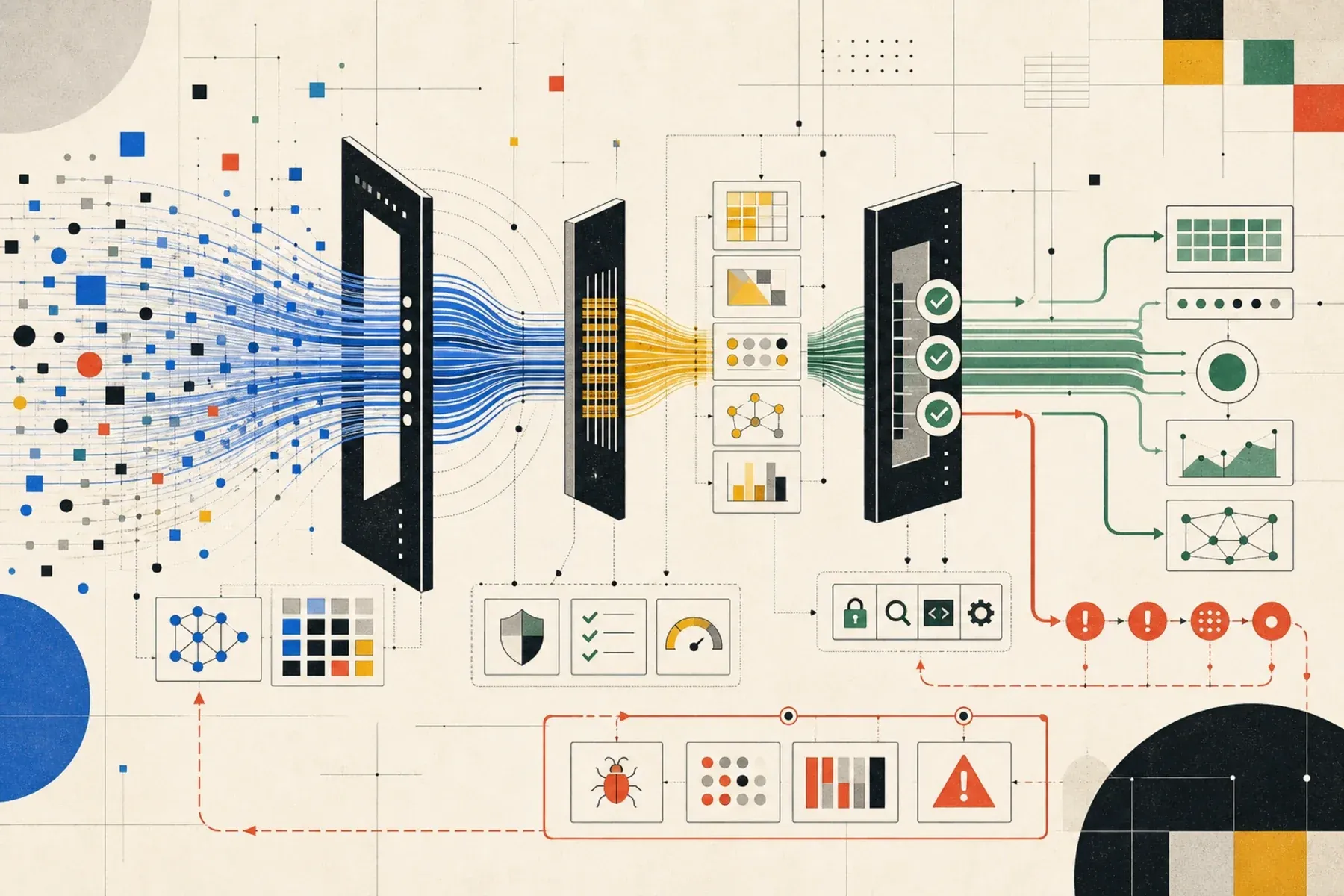
AI coding agents are moving the bottleneck from code production to verification. That means the SDLC needs stronger evidence, testing, risk controls, and maintainability signals.
Why many apparent multi-agent gains are really test-time compute gains, and when extra agents are still worth the complexity.

Gated cyber models may buy defenders time, but history suggests the advantage will not last.

When machines master the ordinary, humans are freed to pursue the extraordinary. From photography to AI music to vibe coding, the same pattern repeats.