
AGI arrived in late 2025.
Not in a sci-fi sense, but in the sense that now drives markets, hiring, and institutions: most knowledge work is now AI-addressable most of the time.
This is an opinion piece, and the evidence is already strong enough to make the call. AGI is no longer a purely future-tense concept.
What I mean by “AGI arrived”
I do not mean flawless intelligence.
I mean a system class that now:
- Handles a broad set of cognitive tasks across domains.
- Matches or beats typical human performance on many of those tasks.
- Is deployed at scale cheaply enough to change how institutions operate.
By that standard, 2025 was the crossover year, and we are already on the other side of it.
The evidence for a 2025 crossover
The Stanford AI Index 2024 already reported that AI systems had exceeded human performance on selected benchmarks in image classification, visual reasoning, and English understanding, while still lagging on harder tasks.
The Stanford AI Index 2025 then showed the next phase: many traditional benchmark families are now saturating, and new harder benchmarks are being created to keep measuring progress. That is exactly what “moving goalposts” looks like in a fast-moving field.
More importantly, task-based evidence beyond classroom benchmarks now confirms the shift.
In RE-Bench (ICML 2025), the best AI agents scored about 4x human experts at a 2-hour budget. But humans scaled better with time: they narrowly exceeded top agents at 8 hours and reached about 2x top-agent scores at 32 hours.
ARC-AGI adds another concrete signal. On ARC-AGI-1, OpenAI’s o3 preview scored 75.7% on the semi-private set under ARC’s public leaderboard budget cap, and 87.5% with much higher compute.
ARC-AGI-2 was specifically designed to re-open headroom in 2025. The top Kaggle private score was 24.03%, the top verified commercial model (Opus 4.5 Thinking 64K) scored 37.6%, and a top verified refinement-loop system scored 54%. As of February 2026, ARC’s public leaderboard data shows a top non-human ARC-AGI-2 score of 84.58%, and ARC Prize is already publicly listing ARC-AGI-3 as the next benchmark track.
METR’s March 2025 long-task study reports a similar operational boundary: current frontier model agents were near 100% on tasks that take humans under four minutes, but below 10% on tasks taking more than about four hours. The 2025 post reported roughly a 7-month doubling time on the original series; the updated v1.1 figures on the same METR page now estimate about 182.7 days all-time (~6 months) and about 122.6 days from 2023 onward (~4 months).
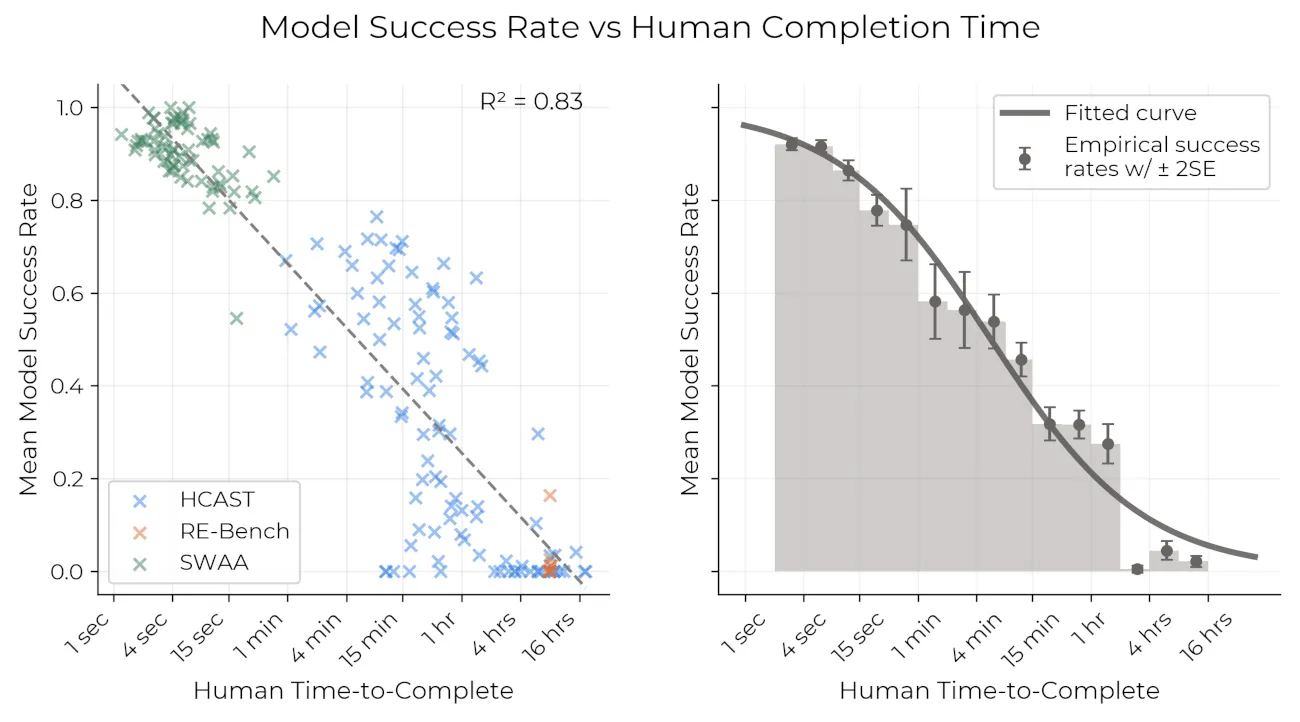 Source: METR long-task benchmark analysis (March 2025).
Source: METR long-task benchmark analysis (March 2025).
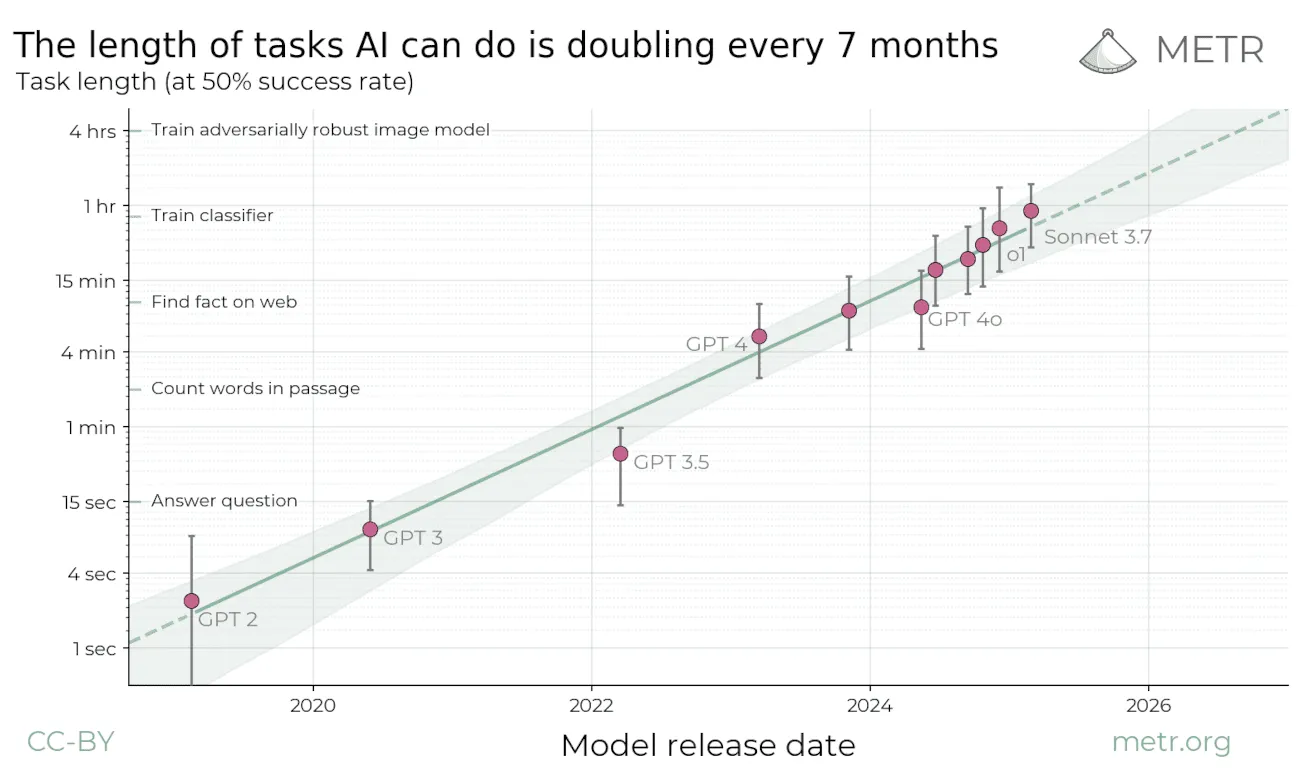 Source: METR long-task benchmark analysis (March 2025).
Source: METR long-task benchmark analysis (March 2025).
That is not “superintelligence”. It does not need to be. It is already economically and operationally general for a huge share of knowledge tasks.
The Turing threshold is no longer hypothetical
A 2025 Turing-test study found GPT-4.5 (with a persona prompt) was judged to be human 73% of the time, while real humans in the same setup were judged human 67% of the time.
You can debate experimental design details. The claim that “AI clearly cannot pass as human” is no longer credible.
On conversation-level behavioural mimicry, the threshold has been crossed.
Yes, intelligence is not evenly distributed
Capability is now abundant. Access and effective use are not.
- Some people have premium models, good workflows, and verification habits.
- Others have weak access, weak prompting support, or no organisational integration.
- Institutions vary wildly in policy, training, and trust models.
This unevenness is measurable. In field evidence such as the large “Generative AI at Work” study, average productivity rose by about 14%, and gains were substantially larger for novice and lower-skilled workers than for top performers. The upside is real, but its distribution is a deployment decision.
So the right statement is not “AI helps everyone equally”. The right statement is “general cognitive capability now exists, and societies must decide how broadly to distribute it”. That is a governance problem, not a capability problem.
Why the AGI definition fight is becoming a distraction
There is still no universally accepted AGI definition in the research community, and there likely will not be one soon. Even recent formalisation attempts begin by acknowledging that ambiguity.
That matters for philosophy. In policy and operations, it is now a distraction.
If systems can already:
- Outperform humans on many benchmarked knowledge tasks.
- Execute most short-horizon professional tasks in key domains.
- Pass as human in controlled conversational testing.
then the serious question is no longer “is this technically AGI?”. The serious question is “how do we govern and deploy this responsibly?”.
What to track instead of AGI arguments
Stop tracking labels. Track operational reality:
- Task horizon: what duration/complexity band can models reliably complete?
- Reliability: how often are outputs correct, calibrated, and reproducible?
- Cost and latency: who can actually afford to use these systems at scale?
- Distribution: which groups gain capability, and which groups are left behind?
- Safety and governance: what guardrails exist for misuse, bias, and systemic dependency?
Those questions drive outcomes. The AGI label does not.
Conclusion
2025 is when AGI became practically real for mainstream knowledge work. That is the decisive fact, even if capability remains unevenly distributed and imperfectly defined.
You can still argue semantics. Meanwhile, the labour market, education systems, and software stacks are already reorganising around AI as default cognition infrastructure.
The urgent work is no longer naming the threshold. It is governing the consequences before distribution failures and safety gaps harden into institutions.
References
- Stanford HAI, AI Index 2024, Technical Performance
https://hai.stanford.edu/ai-index/2024-ai-index-report/technical-performance - Stanford HAI, AI Index 2025
https://hai.stanford.edu/ai-index/2025-ai-index-report - ARC Prize, OpenAI o3 Breakthrough High Score on ARC-AGI-Pub (20 Dec 2024)
https://arcprize.org/blog/oai-o3-pub-breakthrough - ARC Prize, ARC Prize 2025 Results & Analysis (5 Dec 2025)
https://arcprize.org/blog/arc-prize-2025-results-analysis - ARC Prize, Leaderboard data
https://arcprize.org/media/data/leaderboard/evaluations.json - ARC Prize, ARC-AGI benchmark overview (includes ARC-AGI-3 listing)
https://arcprize.org/arc-agi - METR, Measuring AI Ability to Complete Long Tasks (HCAST, 19 March 2025)
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/ - RE-Bench (ICML 2025, PMLR)
https://proceedings.mlr.press/v267/wijk25a.html - Turing Test: AI May Be Better Than Humans at “Imitating” Humans (arXiv:2503.23674)
https://arxiv.org/abs/2503.23674 - A Definition of AGI (arXiv:2507.11430)
https://arxiv.org/abs/2507.11430 - NBER Working Paper w31161, Generative AI at Work
https://www.nber.org/papers/w31161